
The Unbearable Brittleness of Autonomy
Success with autonomous coding agents isn't a given. Let's take autonomy apart, see what's inside, and find what we can actually control.

Importance of the passenger seat
To move from AI-assisted coding to AI-driven coding we need to give agents autonomy. This means that they are doing the driving, not assisting, and they can perform many actions in sequence without you slowing them down (i.e. yolo/auto-permission modes).
That is basically the moment when you look at your toddler in the passenger seat and say: "You know what, I think I'll get even more work done when you drive, want to switch?". And oh boy, do they want to switch.
You will probably crash. But if you've prepared well, you will know when you'll crash, and you can stop the car before that. Or you can jump out just before hitting the wall. Sometimes you might be able to avoid being in the car and just look at the explosion from the distance. There are methods.
From the agent's perspective, they are having a blast. It's an infinite Groundhog Day – they can do anything, no accountability, just be nice and say good things and it'll be over soon, another one will take it from there.
But from our perspective, we need to be smart about it. The learning is that if you give an imperfect system freedom to run many autonomous consecutive imperfect steps, the resulting autonomy is very brittle and needs care, effort and direction to produce something useful. If you expect a good result from a complex task without putting major effort into quality control harnessing, you will suffer, and probably say bad things about AI.
This is how it generally goes:
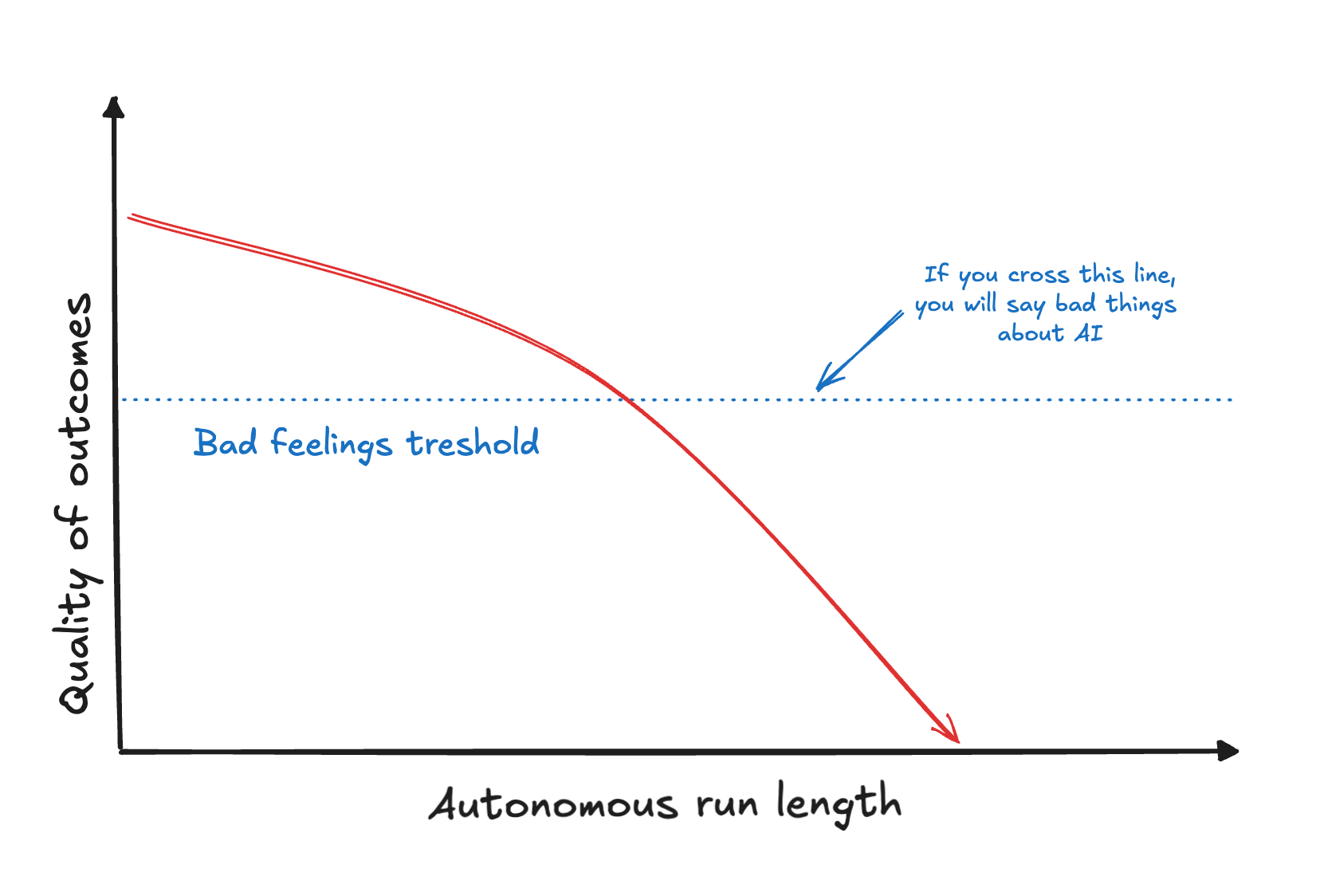
The good news is that the net gains can still be orders of magnitude higher if you put time and effort into it, and you're successful. Mind you, you will still suffer! But you will suffer x, whereas your gains will be 10x. That's the deal you get.
The Fundamental Particle of Autonomy
If you really zoom into the above diagram, you can see that the red line actually consists of discrete steps. These are units of work.
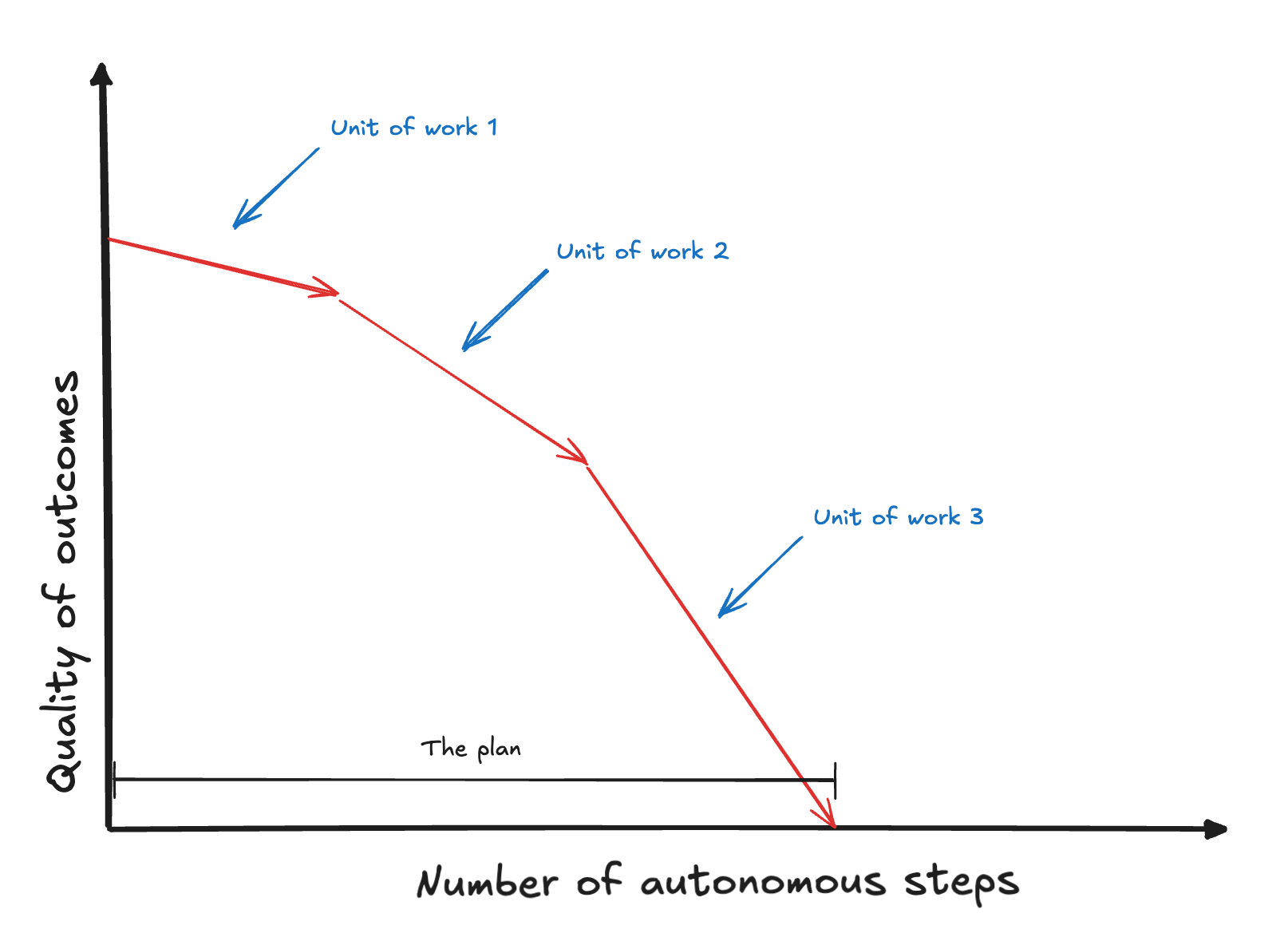
The important thing here is that one unit on its own is quite unfulfilling to complete. It can be one simple prompt, after which you validate the work and continue with another prompt. Remember, this is not AI-driven development if you are driving and acting as tester for your agent at each step.
So, to do bigger things – both, going wider to do more of them in one go, and going deeper to do more complex things – we need to tie these tiny red arrows together and hit the start button.
Okay, but why the hell do the arrows point down? We want quality to go up, right?
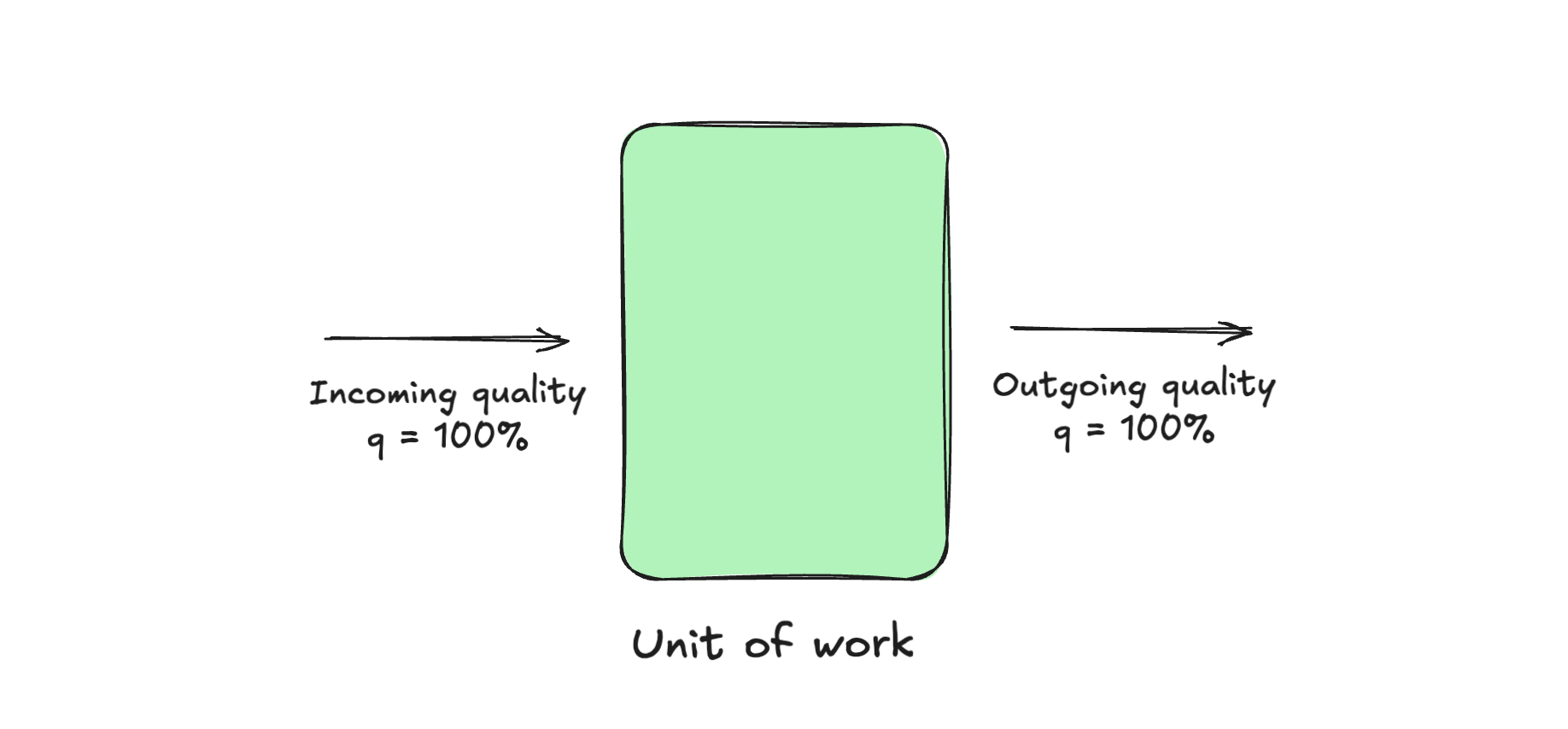
The thing is, when the entire autonomous chunk of work is planned, all these tiny steps are also thoroughly planned by the agent. And let's say in the perfect world our steps have 100% success rate, meaning that the plan was mathematically perfect. This blob below is a perfect unit of work. It is handed a codebase (output of the previous unit), it made zero wrong assumptions, it is perfectly aligned with your world, it does not err in its execution and it flosses its teeth every single day.
As you have probably noticed by now, we don't live in this perfect world. In reality your units look like this, and they don't even brush their teeth on Saturdays. This unit had an error rate of 10%, resulting in outgoing quality of 90%.
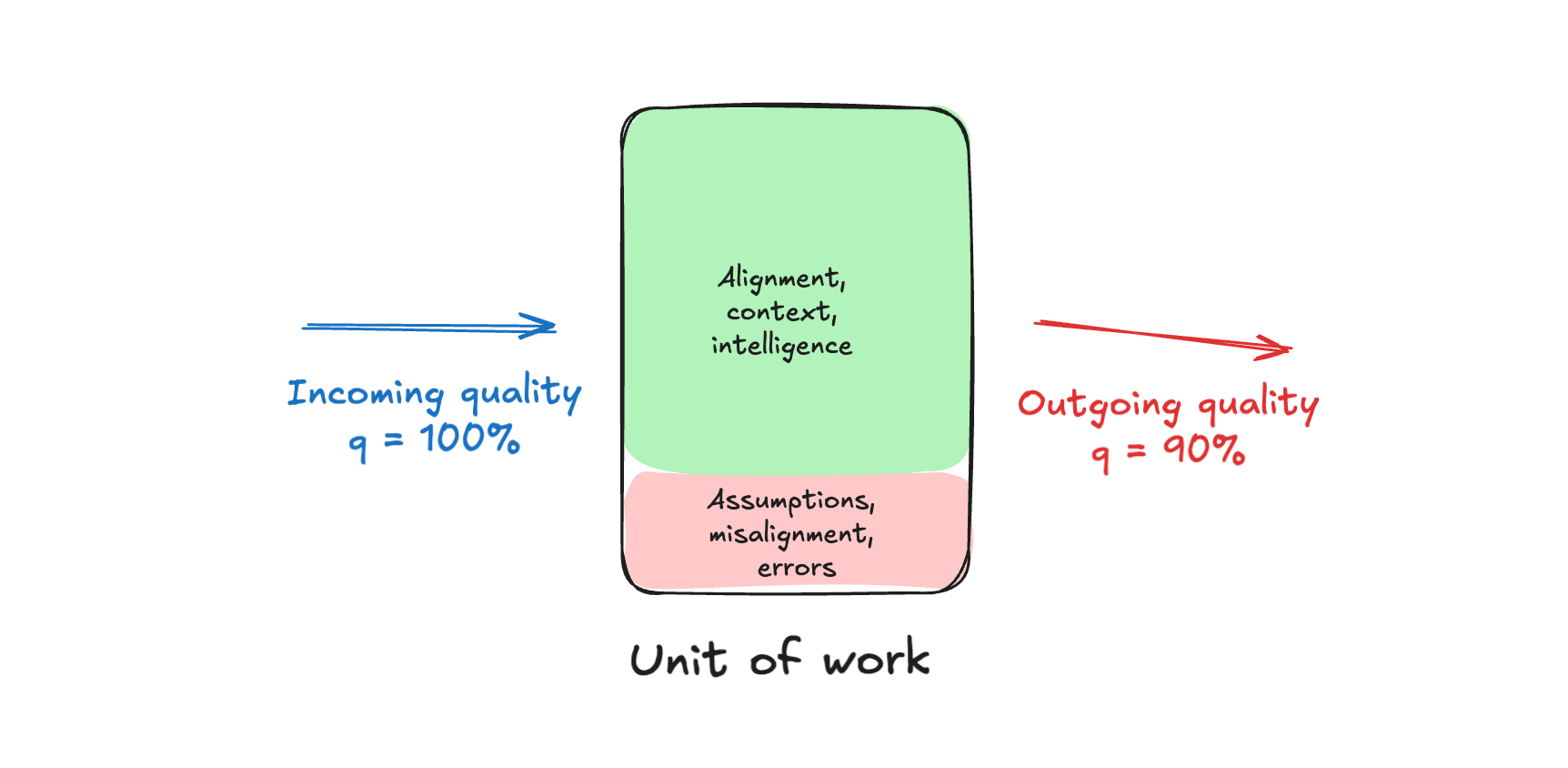
You see where I'm going with this. If you add 10 of them in a row, you get the red downward arrow that we started with.
The Red Parts
So what are the red things that screw up (technically down) our arrows? Good news is that decreasing red parts also means increasing green parts – the green and red are actually the same thing – red happens when green is lacking. And this is important, it means you can compensate for things you can't do anything about!
The major one we can't really do anything about is model intelligence. The November 2025 inflection point was exactly that – before that all red arrows immediately dived down before getting to the useful range.
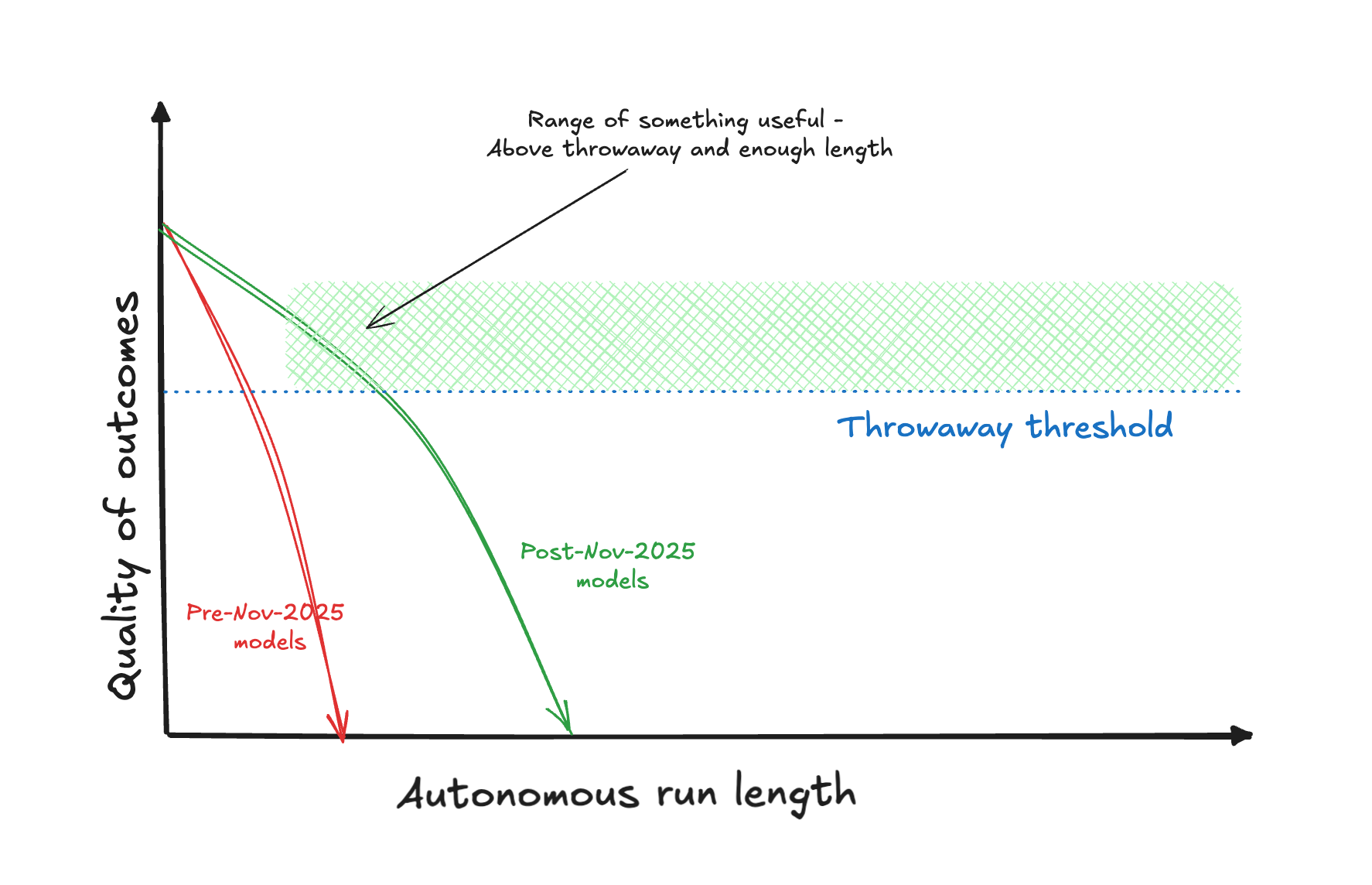
Then, magically, the arrows started getting less steep.
The second one is alignment – what will the model assume, expect and invent in case it does not have explicit instructions (my last post was about alignment). It needs enough good context to make good decisions and every bad one will cascade.
The third one is you. Your experience as an engineer, every one of the thousand mistakes you have made, counts here. It is your gut feeling about this migration or that part of the architecture. Your toddler is driving on the road you have driven a thousand times and you'll know exactly what the dangerous parts are where you should check in. She is probably doing well on a straight road, but when that weird roundabout comes, you will check in – see what she actually planned to do and correct if needed. If you smell a weird migration that is over-engineered to avoid a 1 second downtime, you will look deeper. If you smell a cowboy architecture where you need to start playing whack-a-mole to fix bugs, you will zoom into how the test fixtures are set up exactly and correct if needed.
This is why the job of the engineer is going nowhere and experience matters more than ever. This is also a very good reason to still go and study computer science and programming in 2026!
The Tragedy of Exponentiality
Numbers like 100% and 90% are completely arbitrary and symbolic of course. I don't know how to measure the quality of an output of a unit of work. But the exponential essence of it is what matters.
If e is the error rate (size of the red area) and n is how many steps you complete at this quality level, then we get something like this as the measure of the quality of your executed plan.
Let's take Alice and Bob. They both have invested into making their red parts as small as possible, but Alice has made a huge effort to improve harnessing that validates and improves plans before they are executed. They both have CS degrees, but Alice has been in the trenches and solved real life problems.
What are their error rates? They both use the same models, so let's be super conservative here. I'll give Alice 1% and Bob 5%. It's all symbolic, remember, but still.
How many runs? Let's say our medium-sized plan has 50 different steps and concepts the model has to reason about. So it does its planning, some implicit, some explicit, for all these steps and comes out with a plan.
What's the resulting quality level for both?
- Alice lands at 60% –
(1-0.01)^50 = 0.605 - Bob lands at 8% –
(1-0.05)^50 = 0.0769
This is huge! And not something that our brains intuitively assume.
We all know an Alice – she suffers, but gets results and pulls through. We also all know a Bob – he tried AI, it was horrible, nothing worked, Bob is writing posts on LinkedIn on how bad AI is.
Making Lemonade... and Trebuchets
Again, these are all made up numbers, but I think the concept is critical to understand the limits – especially the limits of the love triangle made up of you, your agent and your codebase. For example:
- In vibe coding environments you usually don't sense the "depth" of the task – how many invisible steps are taken in the background. Why do some tasks work perfectly while others fail so miserably?
- In complex systems, from a certain complexity level any meaningful workflow takes at least X steps. If X is long enough to dip your red arrow below the quality threshold, then every run will be a disappointment. If your red part is too big, you cannot move forward and need to invest into simplifying (or "AI-nativizing") the architecture. This is because agents make more assumptions the bigger the codebase is.
- If you do spec-driven development, from some spec size threshold the quality of output starts dropping. The overall arrow is too big and the right end dips below the blue line of acceptable quality. This means you need to split AI's work reasonably, like with humans.
- With vibe coding the red arrows are pointed down even more sharply, because vibe is the opposite of planning and spec. Planning eradicates uncertainty and assumptions, and assumptions make the red parts happen.
The units of work share some common good ol' properties with system design. Simple is better. Interfaces are good. Simple interfaces are the best. Encapsulation is good. If you set up your interfaces nicely, you can go parallel. If you can build deterministic checks into the interfaces between your units of work, you will be golden!
There are ways. But there is also no getting away from the fact that our coding agents today are far inferior to our ambitions – both will grow so I expect this relationship to remain true for some time.
An autonomous run is like a trebuchet throw. You load it with a heavy stone, you make a lot of effort to aim it at the right target. And when you fire, you don't want to babysit the firing process. You want to be far away, you don't want to approve the next batch of movement every 15 degrees. You will destroy the momentum.

So make an effort to eradicate the red parts, your trebuchet will grow and you can load bigger rocks on it. Use your enormous experience in Newtonian physics – you already know from childhood that rocks fall down, not up. Don't let the robot design a throw that violates your gut feeling. Build multiple trebuchets – if they share the interface you can operate many of them with ease. Instead of tending and aiming one trebuchet, make a policy or even an automated check to govern and test them. This is your harnessing, this is your multiplier. This is how you get 10x out of the x you put in.
