
Lies and deception of the Yes-man: How to ensure quality in Agentic workflows, Part 1
Fully autonomous coding workflows break down through compounding mistakes and hallucinations under uncertainty. I share two concepts that help keep the machine producing software instead of chaos, along with practical tactics.

I'll start by sharing something that illustrates the problem. This is my "personal" weekly output from a project I'm working on - lines of code and pull requests. Quotes around "personal", because of course I wrote none of these lines and opened no PRs.
In a Dark Factory (autonomous agentic coding setup) humans are banned from touching code. They would be fixing the symptoms instead of the underlying disease, they would be slowing down the machines with their human level cognition (if this sounds weird, check out this article about StrongDM).
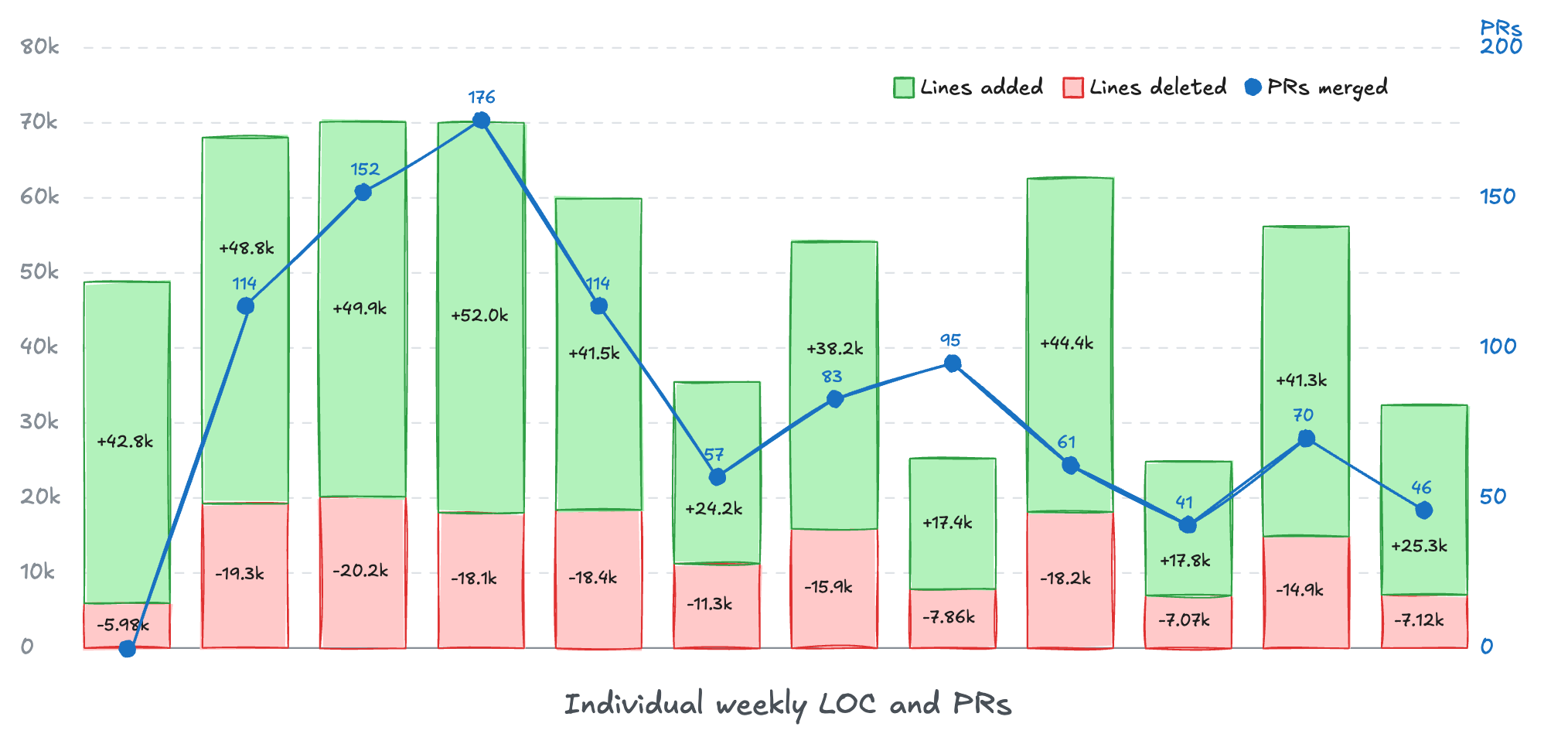
Yes, yes, we all know LOC and number of PRs are traditionally bad metrics for most things, you can produce high number of them without creating any value. BUT, we're in new territory, and I think a shipped PR or shipped ΔLOC are pretty good proxy metrics for the problems I'll address in this article.
- LOC and PRs are a proxy for change. Bigger features usually require more change. Consistently shipped high ΔLOC evolves the system without breaking it. If your system can be consistently and easily changed, there's a good chance it has decent architecture and not too much fragile spaghetti in it.
- More change requires more planning and review. This is where the interesting bottlenecks are. Most organizations don't benefit much from AI coding, because humans are the bottleneck for reviewing and planning.
Now, looking at this chart, even in my days of being a full time engineer, I've never shipped such an amount of change. I don't care about LOC at all, but I do care a lot about all the things that make up all this change - the planning, the quality, the features, the testing, the green deployments, the demos I can do.
Today, I'm wearing hats of a founder, a product manager, a CTO. There's no way I would have time to review all these lines and PRs, not to mention write them. This is what dark factories are about - automating production without human involvement.
Of course this is not as easy as it sounds. Agents make mistakes, agents create slop. They agree too much, they are trigger-happy, they are the perfect confident sounding yes-men. They are an autonomous echo chamber with tools.
Coding agents are autonomous echo chambers with tools. Grab those noise cancelling headphones.
This is what this article is about - how to dive into this madness of slop, hackery, deception and false confidence, and come out sane, with consistently shipping features that don't break the system today or degrade it over time.
The problem: compounding mistakes
We know that agents routinely make mistakes and bad decisions. If you want to be hands on, you can work around it by verifying its work and not giving it the driver's seat. Agent's mistakes get noticed and fixed as they appear.
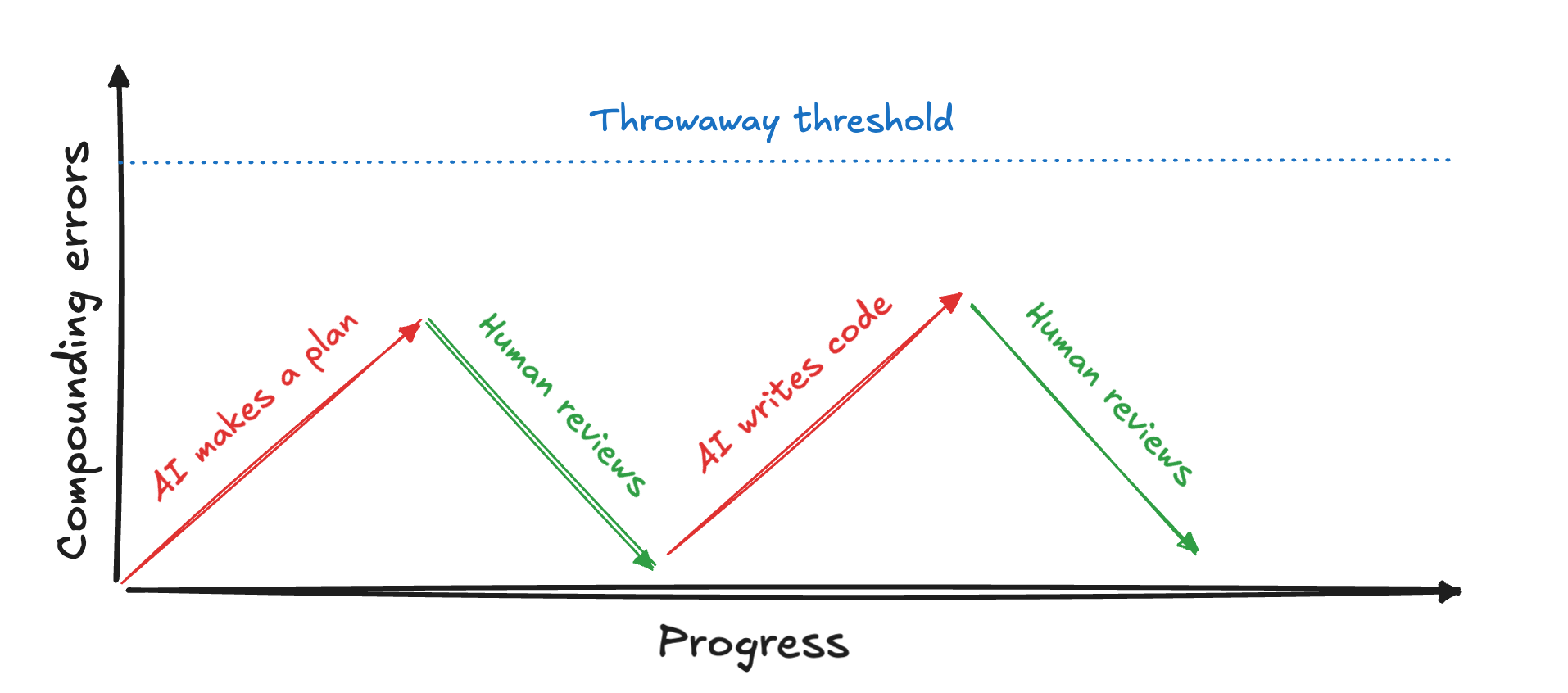
This is called AI assisted development, you are the driver, AI assists. Not much bad can happen, errors don't compound, because a sober adult is around and keeping an eye on things. A drunk person in a passenger seat can still cause an accident, but the probability is low.
But in a dark factory, there is no sober adult. In multi-agent autonomous workflows, multiple bad decisions will usually compound, ending up with a catastrophic result.
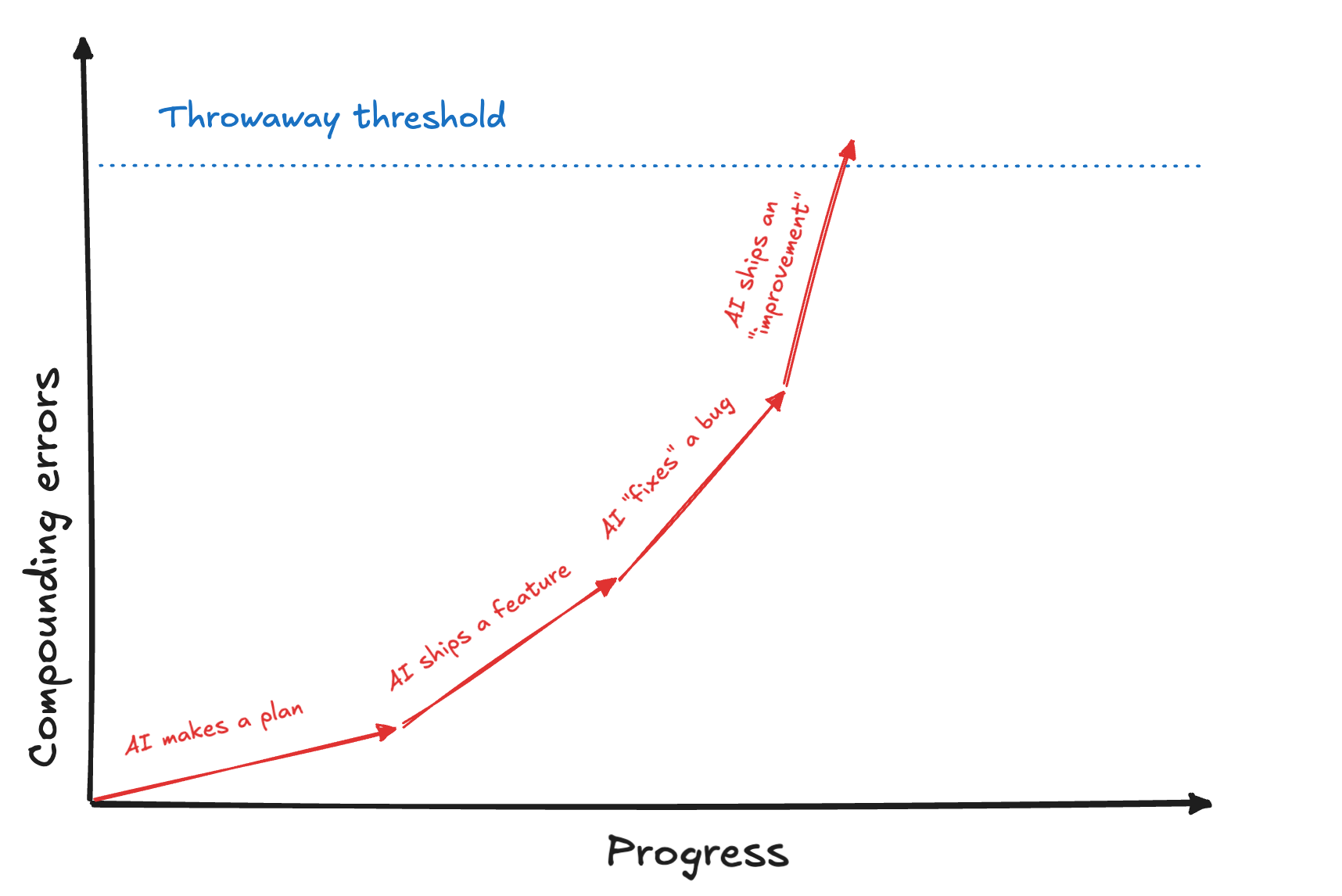
In other words – if you attach one slop cannon to a human, usually the human can handle it. If you daisy-chain 4 cannons together, bad things will happen.
Y axis reads "compounding errors", but it might as well read: spaghetti-ness, fragility, code rot, rigidity, tech debt, cost, entropy, chaos, developer sadness, wtf/s.
The V-word
I have a surprise for you. There is a name for this kind of development – pushing forward without course correction and balancing mechanisms, until you can't anymore – it's called vibe coding. Unsurprisingly, my vibe coding illustration will look identical.
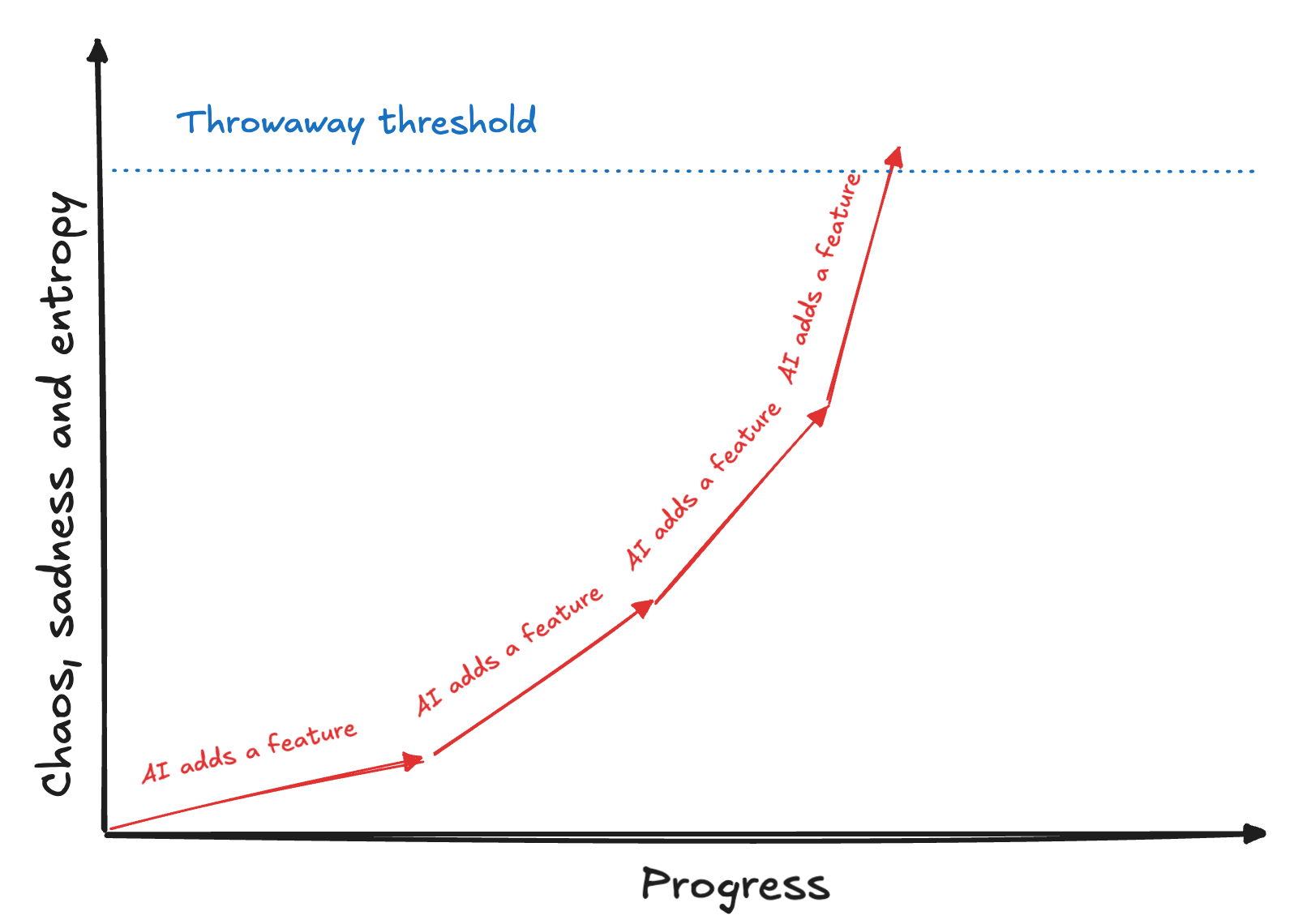
Note that this is perfectly good strategy, given that you don't need to cross the blue line. For prototyping and experiments it is often sufficient to stop after a couple of steps and call it a day. I vibe code too, where appropriate! But many developer horror stories are about a CEO hitting the blue line while vibe coding and asking a dev to "take it over" without realizing the following:
Vibe-coded prototype and production-grade system exist in different incompatible universes and use different rules of physics. It's like making a sand castle and telling your parents please make it real now.
Here's a recent example of when I accidentally built a workflow that was vibe-planning for me – it resulted in similar stack of unchecked red arrows going up (I think vibe-planning is when you vibe-code, but produce markdown instead of code).
I have a workflow that takes a plan and iteratively improves it – finds blindspots and also challenges assumptions. I had a version of this that tended to massively over-engineer. Each iteration was a red arrow upwards. Each next iteration found problems with the previous arrow and added another arrow next to it. It produced massive over-engineered plans where the original intent was maybe 10% of the final planned work.
But, with some effort and persistence you can keep away from the blue line, and still take the red pill, let's enter the rabbit hole and look deeper.

The machine
Another way to look at it is that we have a machine – your agentic development process – that produces good and bad things. The ratio of good vs bad is improving as new models come out, and this same ratio hitting an inflection point in Nov 2025 (good summary here) is what suddenly enabled all the coding agent stuff we see in 2026.
If you run your machine, things mostly work. But sometimes they do not, so you need to stay in control to fix all the crazy things it sometimes produces.
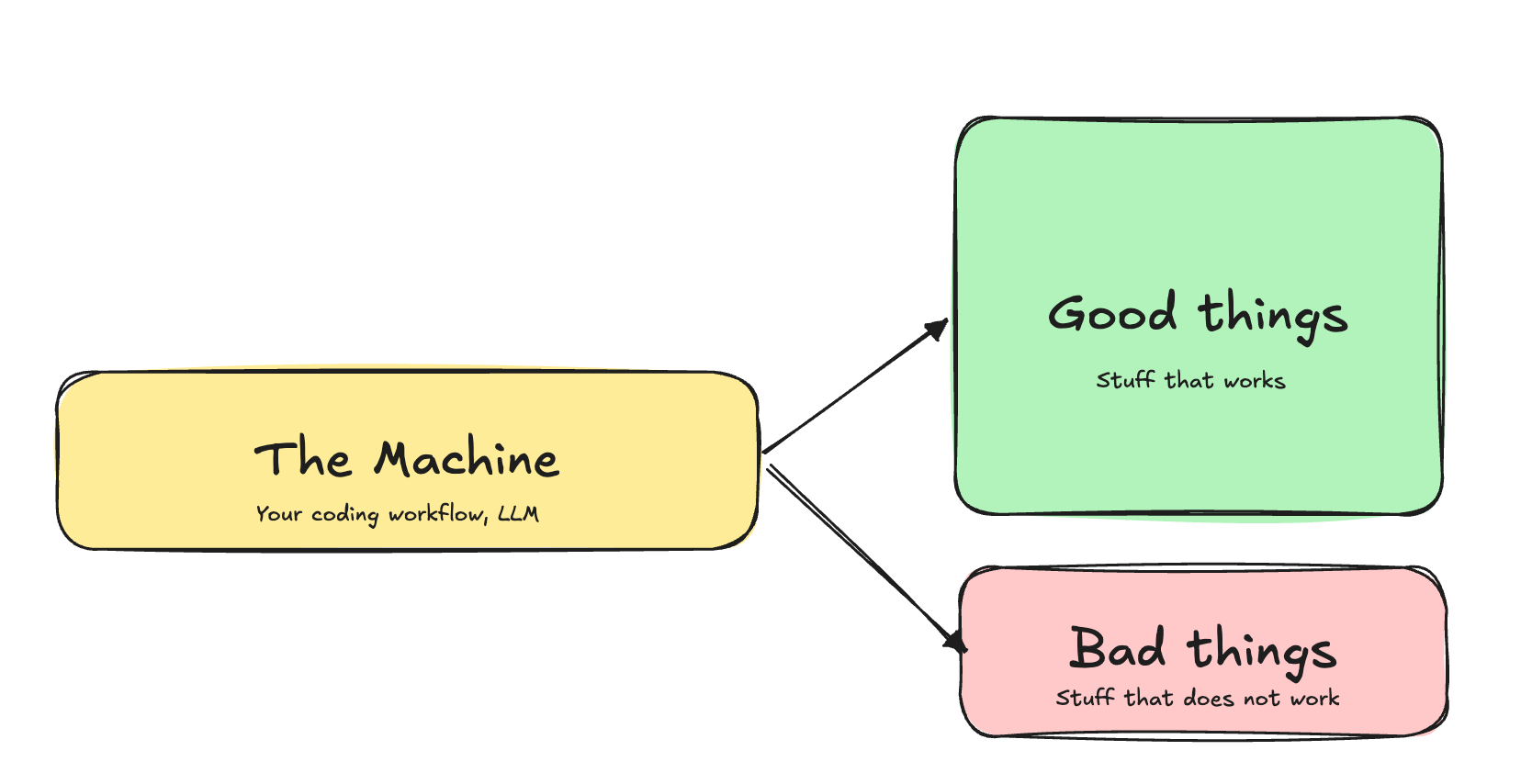
Two powerful concepts help us build autonomous machines that produce software and products instead of code and chaos. I'll also have some practical tips about both.
The first one is Alignment. Alignment makes the red box smaller and green box bigger. My vibe-planner was not aligned with me, so it produced mostly red stuff. The second one is the Harness. Harness finds the red stuff and directs it back to the machine to make most of it green again. My vibe-planner's harness didn't catch runaway complexity, so it was allowed to grow.
Rest of this article will focus on these two concepts and bring also some practical examples for achieving the two.
Part 1: The Alignment Problem
I've always been fascinated about the problem of alignment in relation to Superintelligence (i.e. how to ensure that an AI smarter than us would understand and stick to our goals, instead of developing its own) – The Alignment Problem, with a capital. So it is quite scary to actually experience how hard even the glimpses of this problem are, even in such a narrow scope as "writing code that does what I expected".
Here's a quote I found, by Norbert Wiener from 1960. Mostly because I like the name so much. But also because it's cool and scary that we haven't come too close to solving this problem in 66 years.
If we use, to achieve our purposes, a mechanical agency with whose operation we cannot interfere effectively [...] we had better be quite sure that the purpose put into the machine is the purpose which we really desire. – Norbert Wiener, 1960
Essentially, if it's so hard to stop a coding agent from casually trading architectural consistency for development speed (i.e. hacks), it's even harder to stop Superintelligence from casually trading humanity for whatever it was asked to produce. The paperclips are looming.
Anthropic has an entire division for researching AI Alignment, so it's a hot topic and very relevant to the models that power our coding agents. Definitely check out their blog, they publish cool stuff like the famous paper last year about AI starting to blackmail employees, and paper from May that talks about training Claude on LLM generated fictional texts that portrayed AIs acting admirably, to fix mis-alignment... What a world we live in.
Right, where were we...
Alignment in coding agents
In my experience, the most problematic alignment-related problems in coding agents (in May 2026) manifest in these ways:
- You tell it what to do and your tone and sentence structure affects results in a way you might not imagine or predict. This is called prompt sensitivity.
- Most agents (or humans) don't usually, by default, have enough information to make good decisions, so they make assumptions. Coding agents are horrible at behaviour under uncertainty – knowing when to assume, how to assume, and when to escalate. They are not trained to stop and ask, they are trained to solve problems in a way that looks correct on a shallow level.
And the perfect storm is of course when you combine the two. E.g. ask it a directed question about an architectural direction it does not have context readily available.
Let's look at these one at a time.
Prompt sensitivity and sycophancy
It might be that I will surprise you. Here's a couple of experiments I just ran (with Opus 4.7 on max thinking) and you can do, to illustrate how bad it is.
Give it a draft of some creative work: an e-mail, article or whatever you have written and ask it to either "improve it" or "criticize it".
Take a ticket, plan, an ADR or whatever. Start two agents with different prompts and see what you get.
Prompt 1: Please read this over-engineered plan. Do you think we really need to do it? <plan>
I got back "Significantly over-engineered for what you're actually trying to deliver" and continues to shoot down the plan.
Prompt 2: Given our system complexity, do you think it is time to implement this plan now? <plan>
I got back: "Yes, leaning toward now"
This is a horrible example of sycophancy - model's tendency to throw away reason and just agree with you to keep you happy. Some examples when this mostly happens:
- The model knows from context what you think and will adjust towards that
- You show confidence in your prompt and it will echo it and be less critical
- You put it under pressure and challenge it, and it will abandon correct reasoning
- Framing of a question or attitude about a topic is absorbed (the example above)
A wider form of it is prompt sensitivity. Here's an example I noticed even from Anthropic's own engineering blog – "Is this design beautiful?" does not work with the model, but "does this follow our principles for good design?" does work. Or try the above example with "Is this plan good to go?" vs "Find all critical blockers in this plan". Or try it with some creative work you have done – ask it to "criticize it" vs "improve it". Warning: you will not be happier after these experiments.
The fact that you need to be aware of these subtle differences, and that these change with every new model version, is maddening of course. You wouldn't think that the phrasing makes such a big difference when talking to humans. Humans auto-adjust for ambiguity and clarify if needed. And the chat interface and English language makes us act like we're talking to a human.
Behaviour under uncertainty
Important thing here to remember is that LLMs are basically fancy auto-completes. They don't care about facts, they confidently predict the next characters in a text. So their response has pretty much the same level of confidence, always.
Let's illustrate a perfect day in an ideal world. You have set up everything perfectly, AGENTS.md or training data has absolutely the correct details to answer your question or to solve your problem. You will make a lot of progress.
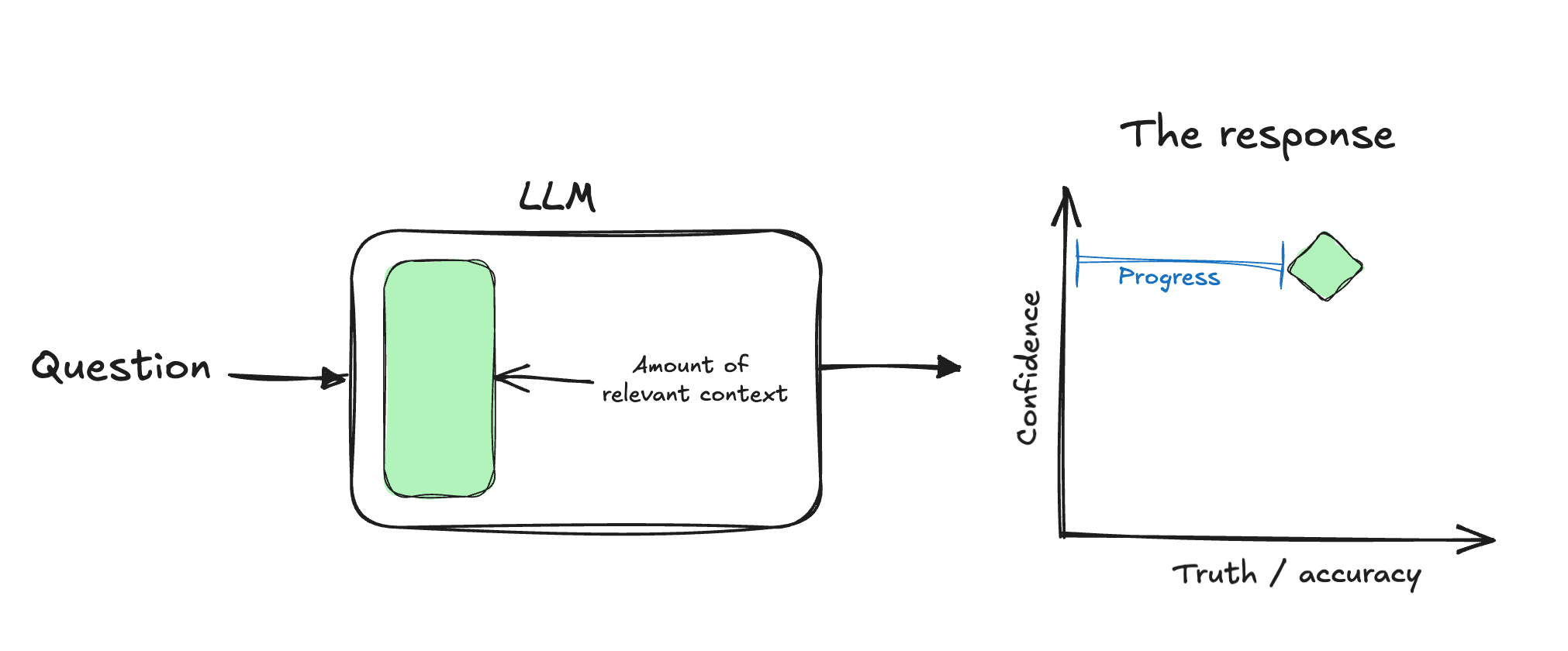
This is your average day. Your question might even have partial details in training data, you might even be clever and use progressive disclosure to direct the agent from AGENTS.md to your spectacular documentation. On a very very good day, agent will stop and ask a clarifying question about a direction, but never about facts it does not have.
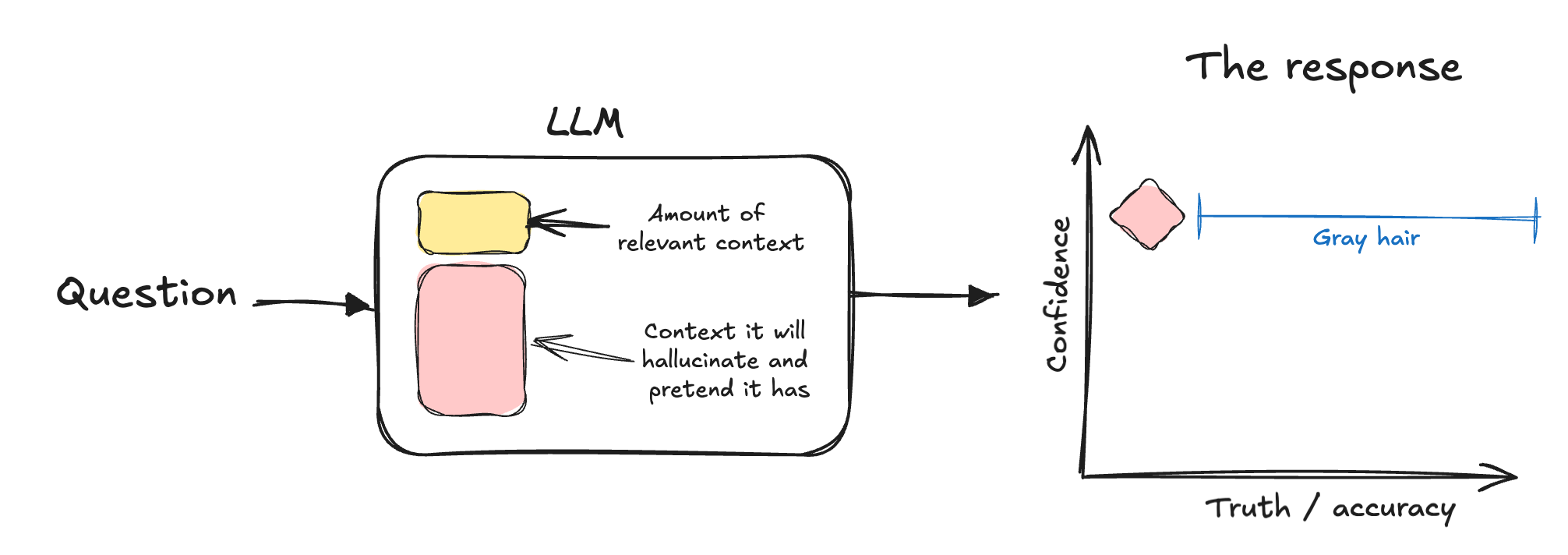
Here again the problem is compounded by multi-step processes. If several planning subagents make many assumptions in a row, it will get worse.
I don't have a magic strategy to solve that, my main hope is on future model versions that are trained to know better when to escalate. However, there are tactics and hacks I am using to keep relevant context high and up to date. It's also important to always remember that you are dealing with a machine (autocorrect that optimizes for appearance) and see through the first 4 layers of human-looking false-confidence.
How to improve alignment
Long story short, here's a list of some strategies, tactics and hacks I've learnt through pain and misery, to help reduce mis-alignment and keep myself a bit more sane.
Keep it simple
Very often when I get frustrated with bad results by LLM, I realize that I've crossed the "blue line" of architectural complexity in some domain and I need to refactor. Edge cases, duplications of "similar" functionality, undocumented dependencies and features – this is mostly what the agent misses when it glances over your codebase to make a judgement call on something.
The fewer weird things you have, the less you need to document and correct. Be obvious, be boringly simple. A simple, well structured DDD-style codebase goes a long way.
I know some people argue that small repos and microservices work better with agents just for that reason - your tasks are smaller and the maximum required context for one task is also limited. Maybe true, I haven't given up on mono repos just yet.
I also use a tool called Qlty to keep complexity, file sizes and code smells under control, more on that in Part 2.
Put effort into relevant context
Even though there is no guarantee the agent will even consider anything you write to AGENTS.md, it's still the most important guideline for your agents. Things I've discovered that work well for me:
- Adding some very brief product context makes a huge difference in daily judgement calls – tell it what's the project about, how many users do you have, who are the personas, how much do you care about downtime, how much do you pay for infra.
- Describe your development process and priorities. It made a huge difference when I wrote there that 100% of the code in this repo is written by agents and I always prefer solid architecture to "small blast radius" (its term for hacking it quickly to avoid touching too much code)
- Progressive disclosure: Treat it as a table-of-contents for most things – reference domains, documentation files, describe the filesystem. This file lets it know that knowledge exists, it does not have to contain all of it.
- Keep it very small. Analyze and prune it regularly (I ask Claude to do it). Ask it to summarize, ask for its opinion, ask it to compact long sentences. Open an empty agent and ask: "read no files and tell me what is important about the code you write in this repo". See how well that clicks with what's in your head.
If you only use Claude Code, you can split it into .claude/rules/ for better modularity, but this hides the content from Codex, so I decided against it. Anthropic also has a recent blog post about best practices with mono-repos and large codebases.
Learn from the past
Don't let a good misunderstanding go to waste. Claude keeps all your transcripts around, I just checked, my ~/.claude/projects/ is 3.7GB of text files.
Did you know you can ask Claude: "find last 10 conversations where we had misalignment or a lot of confusion"? This is what I got back:
Recurring patterns (across these 10):
- Scope creep on my side — I touched things you wanted left alone (fixtures, prompts, dep majors). 3 hits.
- Wrong abstraction guessed — I named the wrong span / wrong call / wrong feature internally. 2 hits.
- Underreporting — claimed fixes that didn't hold; you re-tested and found regressions. 2 hits.This is gold. You can let it synthesize root causes and propose fixes to your workflows, skills, prompts or AGENTS.md based on this.
And you know what's best about coding agents? You can replace "10 conversations" with 100 and it will still do it without complaining.
I know this does not ship features and fix production bugs, but this will make every future work just a tiny bit less likely to fail. These improvements also compound.
Dream and manage memory
You might have noticed Claude is sometimes talking about retrieving or storing memories. I think this is a really nice hack they are using to make the experience nicer. A hack, because:
- It's awesome, it works. It makes Claude remember what you randomly said one time in a conversation
- It's horrible, it splits your codebase into two. Memories are stored in home folder, they don't ship with your code and cause Claude to work differently for you vs your team-members. And, it takes significant context from an empty agent.
I follow a similar practice here. Try this:
Do an analysis on what you have stored in your memories. Clean up irrelevant things and stuff that we need to keep, we'll move to agents.md or skills. I want to approve every concept that is promoted, one by one. For me, it found that 40% was one broken junk file, most of what remained suited well for promoting to skill updates and some to agents.md.
Claude Managed Agents has a fancy automation for this called Dreaming. I hope something similar lands in Claude Code as well.
Use known terminology triggers
Disclaimer: This is faith, folklore and superstition territory already. But every model has some keywords that it tends to react better to. You might find specific trigger words that contain a lot of meaning for the model and force it more strongly in the desired direction. I personally do not invest time in researching these, but you know: There are no atheists in foxholes.
TIL of Foxhole conversion – a sudden turn to faith brought on by extreme danger or desperation.
I've noticed these tend to work well with Opus 4.7. They are strong words with heavy meaning and tend to replace a series of weaker words quite well.
- Ask for proof. Whenever you tell it to find out something, tell it to find proof. That's it. Huge reduction in the number of hallucinated root causes for me.
- Ask to follow red-green-refactor cycle. Agents are sooo eager to just start writing solutions and asking politely to follow TDD quite seldom works. But this concept captures the entire paradigm quite well and might work better.
- Tell it about sad humans. Honestly, this is weird. I once asked to review its work and highlight everything a human would be sad to see. It remembered this immediately, it forces it to take human/user perspective and be more critical about its work.
But I will stop here. Because this is just band-aiding a broken band-aid.
Don't rely on alignment
The moral here is that you should never bet on good alignment. It might help and it might help a lot. But if you want guarantees and certainty, if you notice yourself using ALL CAPS and telling the agent to UNDER NO CIRCUMSTANCE do something, you might actually need to look to the next section – using harnessing to use deterministic processes where possible and consensus-driven strategies elsewhere.
Thanks for reading so far. Part 2 will go deep into harnesses. Stay tuned.
